-
 ClasSup: Supervised image classification
ClasSup: Supervised image classification
ClasSup: Supervised image classification| Presentation and options | Dialog box of the application |
| Syntax |
ClasSup does a supervised classification based on classical classifiers as: minimum Euclidean distance, minimum Manhattan distance and maximum likelihood.
The signatures that define each class are read from SGN files, which typically they will have been generated from the AreaSGN application or as a result of the execution of IsoMM.
The different classification methods need very different runtime. For example, in a test on a laptop with 30 files of BYTE data type and 1517 columns * 1311 rows with data read and written in a USB3 external disk, the runtime is about 5.25" in Euclidean distance and 6.5" in Manhattan distance, while in maximum likelihood it takes 10 times longer.
If it is desired, the classifiers can also generate a distance raster (or probability, according to the classifier used) that has been used as the minimum distance (or maximum likelihood) to classify each pixel of the map. In distance classifiers, the generation of this additional raster may involve that runtime increased at about 60%, while in maximum likelihood at about 11%. Viewing this image in a grey palette it has to be kept in mind the following:
In case of minimum distance classifiers, it works starting from desired class centers. If working with normalized distance is desired, the input variables have to be normalized.
In the case of maximum likelihood classifier, it uses the classical criterion of Bayesian probability starting from the centers of classes and their desired variance-covariance matrices.
Orientation on the meaning of the distances used in the classification processes
In some options of the ClasSup, as well as in other classifiers such as IsoMM or kNN, calculations of statistical distances such as Euclidean distance are made. In this case, the Euclidean distance is calculated from a problem pixel ‹‹central reference values›› which can be the means class center vector (for example in the case of a minimum distance classifier or the IsoMM), or they can be the vector of values of a training pixel kNN"ClaskNN.htm">kNN classifier).
These distances for the "winner" category can be obtained, in each pixel, in the file of distances provided by some applications of MiraMon image digital classification. The following table shows how to interpret different values of these distances; In all cases it is a classification with 36 variables and in which in some pixels instead of the classification with 36 variables it has been done with 24 variables (for example because in some of the different dates used for the classification, in those pixels there were clouds). In addition, the variables present real values (non integers) bounded between 0 and 100; An example of this transformation would be that the pixels of a variable that is a normalized difference vegetation index, NDVI, typically between -1 and 1, have been transformed (multiplying by 50 and adding 50) so that their values are between 0 and 100; a second example would be that bands of reflectance, typically between 0 and 1, have become values between 0 and 100 (multiplying them by 100 and becoming percentages of reflectance).
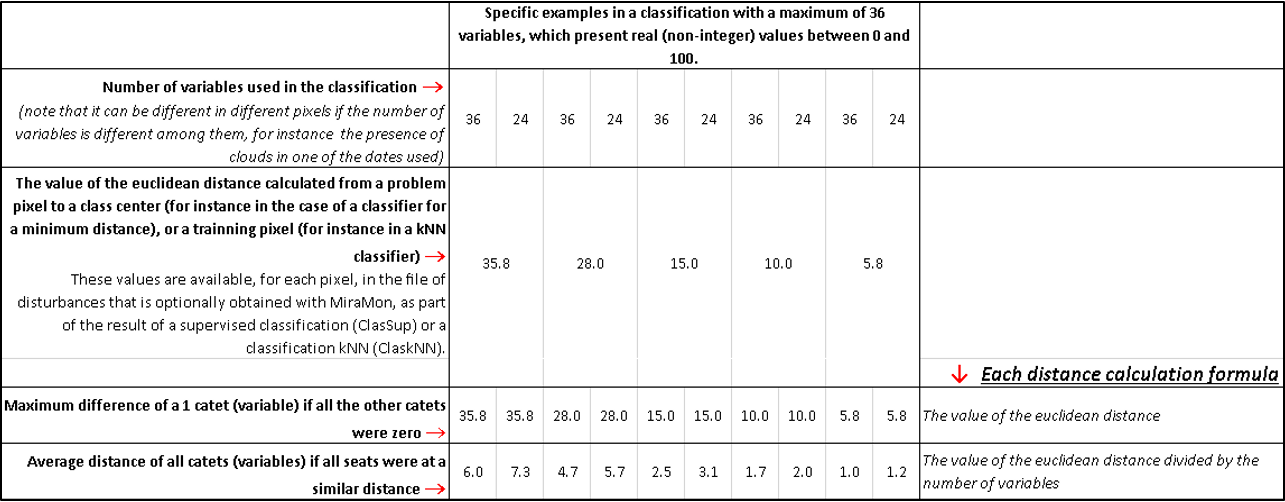
It is proposed to interpret to interpret a distance 35.8 obtained in a pixel classified thanks to 36 variables available. In this case, it can be imagined that the situation may vary between the pixel problem being "far from" the central reference values referred to above, or that the pixel is very close (virtually distance 0) to all the variables used, except one, that accumulate virtually the whole distance. In the first case, in the table it can be observed that the distance must be interpreted as an average distance of 6.0; it is quite likely that the pixel is poorly classified, because with average spectral differences, in all those variables that are responsive in spectral bands at the different dates in which the images were captured, 6% reflectance, hardly the pixel is "similar" to the class. In the second case, in the table it can be observed that the distance to one of the variables is 35.8 (on a total route of 100); it is also quite likely that the pixel is poorly classified if one of the variables has a value so far from the reference value. If this value of distance 35.8 has been obtained in a pixel classified thanks to 24 available variables, the situation of "average distance to the different variables" is still worse, because it becomes a 7.3 instead of a 6.
Next we can interpret a situation at the other end: a pixel classified with a distance 5.8 based on 36 variables. As can be seen in the table, the average distance is only 1.0, that is, very close, and if that it was one of the 36 variables that were very different while the others were practically identical, this variable "disagreeing" would only be at a distance 5.8 (on a total route of 100). If the pixel has been classified thanks to 24 variables available, the situation is not much worse: in the case of the mean distance a value of 1.2 it is obtained, which also indicates a very close average similarity in the 24 variables.
The other intermediate cases in the table can help to understand, in the same terms, in cases where we obtain intermediate distance values between the two examples discussed (35.8 and 5.8).
Neither the maximum number of variables to be considered nor the size of the files are restricted except for the capabilities of the system. For example, in September 2013, ratings were made with maximum likelihood based on 47 "integer" images of 8115 columns x 8757 rows, with satisfactory results in about 90 'of execution although they contained NoData and that also an image of probabilities was generated simultaneously in the classification itself.
Additionally, the application allows the calculation of the Transformed Divergence (TD), instead of making a classification it is written in a file the covariance matrices and correlations values for each class and the TD between all signatures (classes) provided. According to Swain (1973), when TD=2 the probability of separation between classes reaches values > 90%.
For additional technical information, the comments of the IsoMM application can be consulted.
By default, this application loads all images in memory, which allows performing processes in a more agile way. However, in computers with a few resources regarding the size of images, this strategy could be unviable. Due to this, the option "Do not upload images in memory" allows indicating the application that in the processes it keeps in memory only those data needed in each moment, nor that implies a slowdown of the running. The application commutes automatically to this mode if it does not have enough available memory, so usually, there is no need to activate it specifically.
This application is parallelized, both in versions of 32 and 64 bits, so it is possible that it distributes the work between the available processor cores in the computer where it runs. For example, a computer that has two processors of 20 cores each, the time needed to obtain the results can be divided almost into 40 by using all available cores, which can be done with the corresponding parameter stated by "MAX"; when the number of cores to use is MAX, the application used all the cores. Although, sometimes the choice of not compromising the whole capacity of the computer calculations can be preferred, stating SUB_MAX (which will leave a free processor for other performed tasks) or by choosing a concrete inferior numerical value, in all cases through the option "Number of processor cores to be used". Asking for more cores than the actually available is also possible, creating other virtual ones, but this does not speed the procedure, but in the contrary. Windows Task Manager allows knowing the total number of cores of the computer, and it also can be known by running the application in MAX mode, because it will state on-screen how many cores is using.
More information can be consulted at the following reference:
Swain, P.H. (1973) A Result from Studies of Transformed Divergence. LARS Tech Report Number 050173. https://docs.lib.purdue.edu/larstech/42/

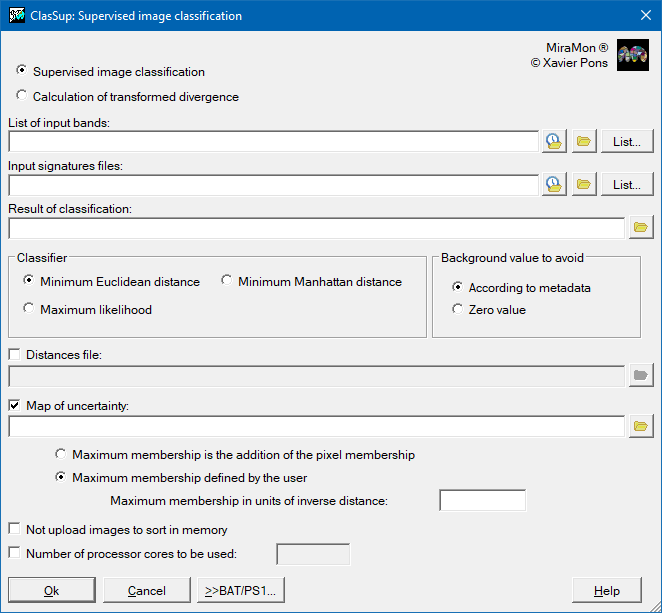 |
| ClasSup dialog box |