-
 ClasSup: Classificació supervisada d'imatges
ClasSup: Classificació supervisada d'imatges
ClasSup: Classificació supervisada d'imatges| Presentació i opcions | Caixa de diàleg de l'aplicació |
| Sintaxi |
ClasSup fa una classificació supervisada en base a classificadors clàssics com: mínima distància euclidiana, mínima distància de l'Eixample i màxima versemblança.
Les signatures que defineixen cada classe es llegeixen de fitxers SGN, que típicament hauran estat generats a partir de l'aplicació AreaSGN, o bé com a resultat d'una execució d'IsoMM.
El temps d'execució és molt diferent entre els diferents mètodes classificadors. Així, en una prova sobre 30 fitxers BYTE de 1517 columnes * 1311 files en un portàtil amb les dades escrites i llegides a un disc extern USB3 els temps són de l'ordre de 5.25" en distància euclidiana i de 6.5" en distància de l'Eixample, mentre que en màxima versemblança els temps es multipliquen pràcticament per 10.
Si es desitja, el classificador també genera un ràster amb la distància (o probabilitat, segons el classificador emprat) que ha estat utilitzada com a mínima distància (o com a màxima probabilitat) per a classificar cada píxel del mapa. En els classificadors de distància la generació d'aquest ràster addicional pot implicar un increment de temps d'execució al voltant d'un 60%, mentre que en el de màxima versemblança d'un 11%. En visualitzar aquesta imatge amb una paleta de grisos cal tenir present el següent:
En el cas dels classificadors de mínima distància es treballa a partir dels centres de classes desitjats. Si es desitja treballar amb distàncies normalitzades, cal normalitzar les variables d'entrada.
En el cas del de màxima versemblança s'utilitza el criteri clàssic de probabilitat Bayesiana a partir dels centres de classes desitjats i les seves matrius de variància-covariància.
Orientació sobre el significat de les distàncies emprades en els processos de classificació
En algunes opcions del ClasSup, així com en altres classificadors com IsoMM o kNN, es fan càlculs de distàncies estadístiques com la distància euclidiana. En aquest cas es calcula la distància euclidiana des d'un píxel problema a uns ‹‹valors centrals de referència ›› els qual poden ser el vector de mitjanes d'un centre de classe (per exemple en el cas d'un classificador per mínima distància o a l'IsoMM), o poden ser el vector de valors d'un píxel d'entrenament (per exemple en un classificador kNN).
Aquestes distàncies per a la categoria "guanyadora" es poden obtenir, en cada píxel, en el fitxer de distàncies que proporcionen algunes aplicacions de classificació digital d'imatges del MiraMon. La taula següent mostra com interpretar diversos valors d'aquestes distàncies; en tots els casos es tracta d'un a classificació amb 36 variables i en la qual en alguns píxels en comptes de fer-se la classificació amb 36 variables s'ha hagut de fer amb 24 variables (per exemple perquè en alguna de les diferents dates utilitzades per a la classificació, en aquells píxels hi havia núvols). A més, les variables presenten valors reals (no enters) acotats entre 0 i 100; un exemple d'aquesta transformació seria que els píxels d'una variable que és un índex de vegetació de diferència normalitzada, NDVI, típicament, entre -1 i 1, s'han transformat (multiplicant-los per 50 i sumant-los 50) per tal que els seus valors estiguin entre 0 i 100; un segon exemple seria que bandes de reflectància, típicament entre 0 i 1, s'han convertit en valors entre 0 i 100 (multiplicant-los per 100 i esdevenint percentatges de reflectància).
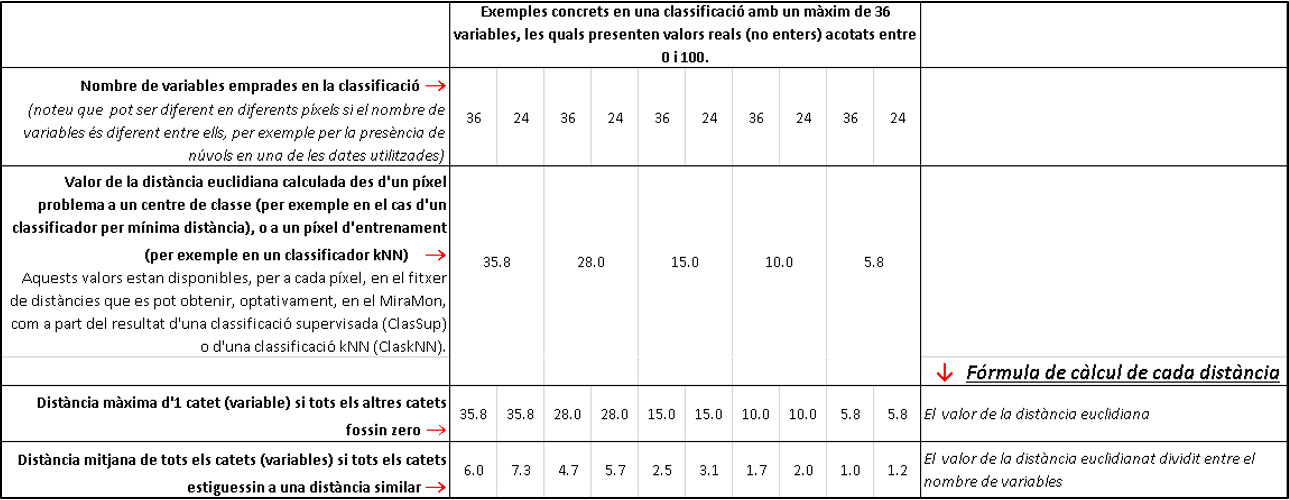
Es proposa interpretar una distància 35.8 obtinguda en un píxel classificat gràcies a 36 variables disponibles. En aquest cas es pot imaginar que la situació pot oscil·lar entre que el píxel problema sigui "mitjanament lluny" dels valors centrals de referència referits més amunt, o que el píxel sigui molt proper (pràcticament a distància 0) de totes les variables utilitzades, excepte d'una, que acumuli pràcticament tota la distància. En el primer cas, a la taula s'observa que la distància cal interpretar-la com una distància mitjana de 6.0; realment és força probable que el píxel estigui mal classificat, perquè amb diferències espectrals mitjanes, en totes aquelles variables que són respostes en bandes espectrals en les diferents dates en què s'han captat les imatges, d'un 6 % de reflectància, difícilment el píxel és "similar" a la classe. En el segon cas, a la taula s'observa que la distància d'una de les variables és 35.8 (sobre un recorregut total de 100); realment també és força probable que el píxel estigui mal classificat si en una de les variables té un valor tan allunyat del valor de referència. Si aquest valor de distància 35.8 ha estat obtingut en un píxel classificat gràcies a 24 variables disponibles, la situació de "distància mitjana a les diferents variables" encara és pitjor, perquè esdevé d'un 7.3 en comptes d'un 6.
A continuació es pot interpretar una situació a l'altre extrem: un píxel classificat amb una distància 5.8 en base a 36 variables. Com es pot veure a la taula, la distància mitjana és només d'1.0, és a dir, summament propera, i si fos una sola de les 36 variables que fos molt diferent mentre les altres fossin pràcticament idèntiques, aquesta variable "discordant" només estaria a una distància 5.8 (en un recorregut total de 100). Si el píxel s'ha classificat gràcies a 24 variables disponibles la situació no és gaire pitjor: en el cas de distància mitjana s'obté un valor d'1.2, que també indica una similitud mitjana molt propera en les 24 variables.
La resta de casos intermedis de la taula poden ajudar a entendre, en els mateixos termes, en casos en què s'obtinguin valors de distància intermedis entre els dos exemples comentats (35.8 i 5.8).
Ni el nombre màxim de variables a considerar ni la grandària dels fitxers estan acotats excepte per les capacitats del sistema. Per exemple, el setembre de 2013 es van fer classificacions de màxima versemblança en base a 47 imatges integer de 8115 columnes x 8757 files, amb resultats satisfactoris en uns 90' d'execució malgrat que contenien sensedades i que també es generava una imatge de probabilitats simultània a la classificació en sí.
Addicionalment, l'aplicació permet el càlcul de la Divergència Transformada (DT), que en comptes de fer una classificació escriu en un fitxer els valors de les matrius de covariància i de correlacions per a cada classe, així com la DT entre totes les signatures (classes) proporcionades. Segons Swain (1973), quan DT=2 la probabilitat de separació entre classes assoleix valors > 90 %.
Per a informació tècnica addicional, es pot consultar els comentaris de l'aplicació IsoMM.
Per defecte aquesta aplicació carrega totes les imatges en memòria, el que li permet realitzar els processos de manera més àgil. Tanmateix, en ordinadors amb pocs recursos respecte de la grandària de les imatges aquesta estratègia pot no ser viable. És per això que l'opció "No carregar les imatges a classificar en memòria" permet indicar a l'aplicació que en els processos mantingui en memòria només aquelles dades que necessita en cada moment, ni que això impliqui un alentiment de l'execució. L'aplicació commuta automàticament a aquest mode si no té prou memòria disponible, per la qual cosa habitualment no cal activar-lo expressament.
Aquesta aplicació està paral·lelitzada, tant en les versions de 32 com de 64 bits, amb la qual cosa és possible que distribueixi la feina entre els nuclis de processador disponibles en l'ordinador on s'executa. Si, per exemple, es disposa d'un ordinador amb dos processadors de 20 nuclis cadascun, es pot arribar a dividir gairebé entre 40 el temps necessari per a obtenir els resultats, utilitzant tots els nuclis disponibles, cosa que es pot fer amb el paràmetre corresponent en un valor indicat per "MAX"; quan s'indica que el nombre de nuclis a emprar és MAX, l'aplicació utilitza tots els nuclis. Tanmateix, de vegades es pot preferir no comprometre tota la capacitat de càlcul de l'ordinador i indicar SUB_MAX (deixarà un processador lliure per a altres coses que s'estiguin fent) o indicar un valor numèric concret inferior, en tots els casos a través de l'opció "Nombre de nuclis de processador a utilitzar". Demanar més nuclis que els realment disponibles és possible, creant-ne de virtuals, però això no accelera el processat, sinó el contrari. L'Administrador de tasques del Windows permet conèixer de quin nombre total de nuclis disposa l'ordinador, i també pot saber-se executant l'aplicació en mode MAX, ja que indicarà per pantalla quants nuclis està utilitzant.
Per a més informació es pot consultar la següent referència:
Swain, P.H. (1973) A Result from Studies of Transformed Divergence. LARS Tech Report Number 050173. https://docs.lib.purdue.edu/larstech/42/

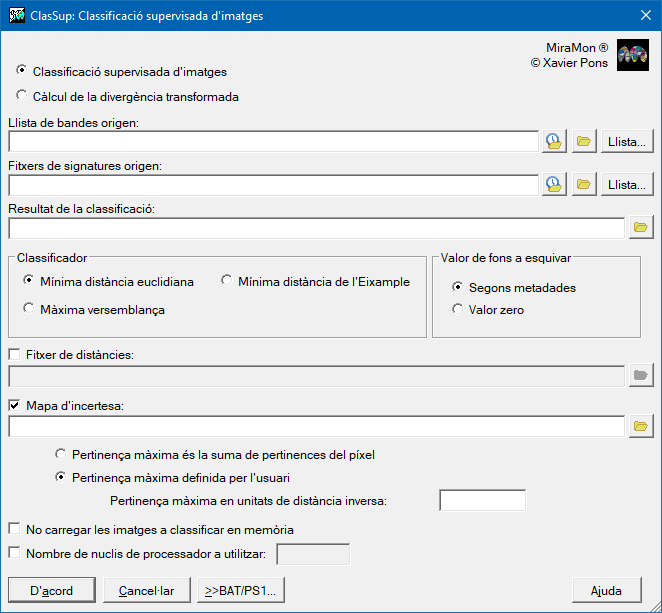 |
| Caixa de diàleg del ClasSup |