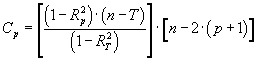-
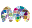 RegMult: Regresión multivariante e interpolación de residuos
RegMult: Regresión multivariante e interpolación de residuos
RegMult: Regresión multivariante e interpolación de residuos| Presentación y opciones | Caja de diálogo de la aplicación |
| Sintaxis |
El modelo aplica regresión lineal múltiple de forma que la variable dependiente Y se intenta obtener de las variables independientes xn, a partir de una expresión del tipo:
![]()
Los coeficientes a0, a1,... an se ajustan por mínimos cuadrados. La aplicación ofrece la posibilidad de añadir una interpolación espacial de los residuos resultantes de la regresión múltiple, de forma que en muchos casos se mejora el poder predictivo por como la interpolación puede recoger una parte importante de la variancia no explicada por el modelo de regresión múltiple.
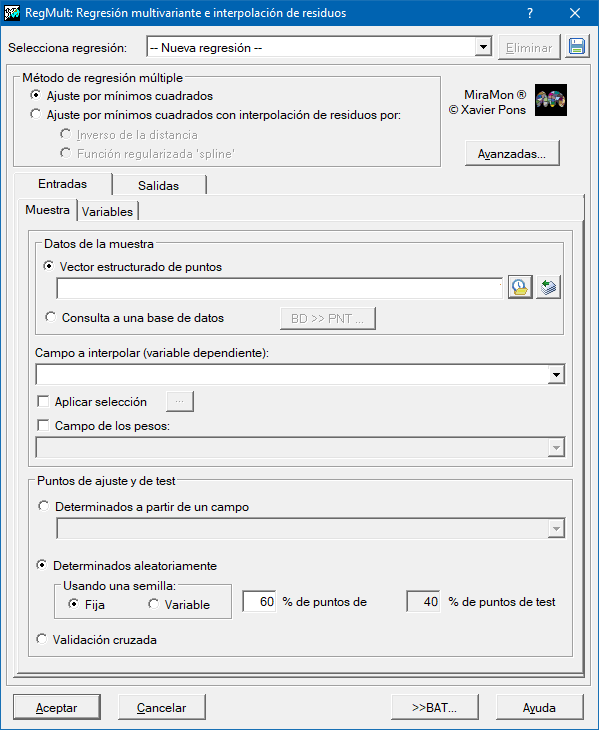
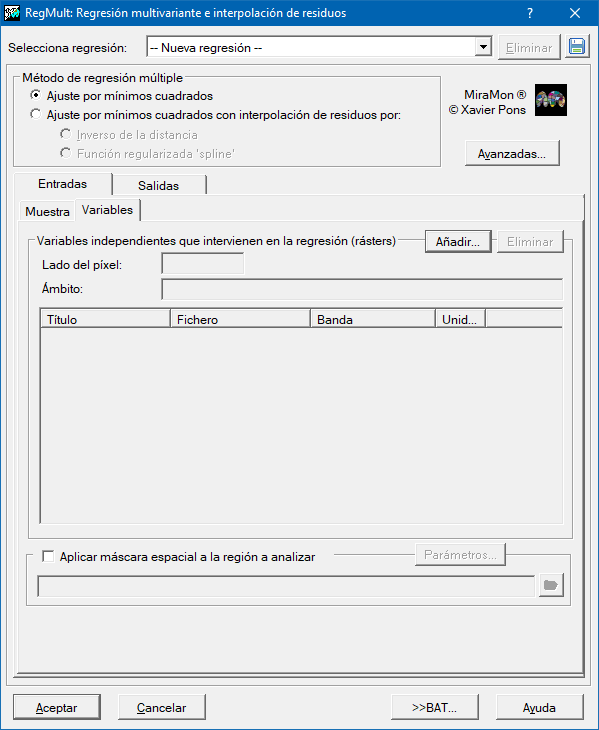
Para determinar los coeficientes de la regresión es necesario proporcionar un conjunto de muestras donde se conocen la variable dependiente en localizaciones concretas (puntuales) y el conjunto de las posibles variables independientes. Estas muestras se proporcionarán bien en un fichero estructurado de puntos PNT, o en una tabla en formato DBF, o bien en una tabla en cualquiera de los formatos accesibles mediante un driver ODBC (Open DataBase Connectivity). Las variables independientes deben proporcionarse como rásters en formato IMG del mismo ámbito geográfico y tamaño de píxel. El resultado predictivo será también un ráster en formato IMG.
El proceso para elaborar el ráster resultado consta de dos fases (o de una única fase en la versión simplificada del algoritmo): la regresión y la interpolación.
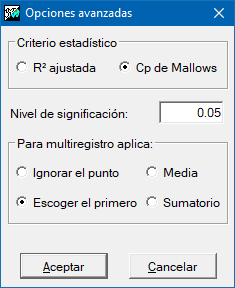
El procedimiento de regresión es, de hecho, un proceso iterativo de ajuste de todas las regresiones posibles: desde la regresión con todas las variables independientes inicialmente introducidas hasta las regresiones con una única variable independiente. Analizando los parámetros estadísticos de cada regresión y, en función del criterio escogido (mejor coeficiente R2 ajustado o Cp de Mallows), se obtiene la que se considera mejor regresión de todas (siempre que se supere el mínimo umbral de significación exigido).
|
n: número de puntos de ajuste k: número de variables independientes R2: coeficiente de determinación |
p: número de variables independientes seleccionadas T: número máximo de variables independientes n: número de puntos de ajuste |
Durante el procedimiento de selección de la regresión óptima, la aplicación informa de los parámetros estadísticos de la regresión con todas las variables independientes introducidas y de los parámetros estadísticos de la regresión seleccionada (evidentemente solo si las dos soluciones no son la misma) y así poder evaluar cómo mejora la regresión seleccionada al eliminar alguna variable que se ha detectado que es poco significativa.
Si el usuario ha seleccionado la opción de sólo regresión multivariante, el modelo resultado se generará calculando en todo el ámbito de estudio la solución de la regresión seleccionada a partir de los coeficientes ajustados aplicados a las variables independientes, las cuales están definidas necesariamente en todo el ámbito de estudio.
Si el usuario ha seleccionado obtener el modelo con el algoritmo completo (regresión e interpolación de residuos), habrá una segunda fase consistente en el cálculo de los residuos de la muestra de puntos de ajuste. Los residuos se obtienen calculando las diferencias entre el modelo predicho por la regresión multivariante y el valor conocido de la variable dependiente. Estos residuos conocidos solo en las localizaciones de los puntos de ajuste, se extenderán por todo el ámbito de estudio mediante una interpolación. El usuario podrá elegir entre dos métodos de interpolación: Inverso de la distancia ponderada (IDW) o Función regularizada spline. Se pueden consultar los parámetros y las características de ambas metodologías en InterPNT.htm.
Es importante la búsqueda del juego de parámetros que dará lugar a la óptima interpolación de los residuos. Los resultados de la interpolación, y del modelo en conjunto, pueden variar de forma significativa al aplicar un juego de parámetros u otro. En este sentido, es muy aconsejable reservar una muestra independiente de los puntos con datos para realizar el test de verificación. Este test consistirá fundamentalmente en calcular el RMS (raíz de la mediana del error cuadrático) total de los puntos de test, verificando que no haya ningún punto en particular con un error excesivamente elevado. Este indicador (RMS) constituye una buena base para aceptar un determinado juego de parámetros. Otros criterios complementarios podrían ser la evaluación de la presencia de artefactos en la interpolación, la apreciación de algún error sistemático, etc.
Para facilitar el análisis, que debe dar lugar al mejor modelo posible, la aplicación ofrece la posibilidad de generar dos capas resultado. La primera, es una capa vectorial de puntos que contiene aquellos puntos válidos con datos que, o participan en el ajuste y posteriormente se usarán para interpolar los residuos conocidos, o bien sirven de test para validar la solución interpolada. Para los puntos de test se informa, en la base de datos, de la diferencia entre el valor conocido y el predicho por el modelo (regresión+interpolación), y para los puntos de ajuste se informa del residuo obtenido como la diferencia entre el valor conocido y el valor predicho (sólo regresión). La siguiente ilustración muestra estos detalles:
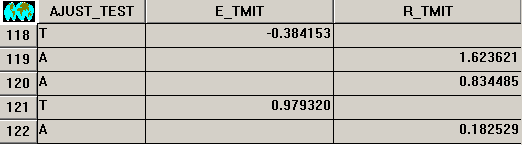
La otra capa resultado, opcional e informativa, es el ráster resultado de la interpolación de los residuos. Una inspección de dicha capa servirá para analizar en profundidad la fase de interpolación desligada de la regresión. Puede servir para analizar si la interpolación ha generado artefactos no deseados, valores fuera de rango en exceso, zonas con excesiva variabilidad, etc. También puede ser una interesante fuente para conocer e investigar las zonas que presentan variabilidad no recogida adecuadamente por las variables independientes.
En principio, todos los puntos que tengan datos válidos dentro de la zona de estudio del fichero PNT con las muestras se usarán bien como puntos de ajuste o bien como puntos de test. Así mismo, la aplicación permite filtrar aquellos datos que no se consideren apropiados aplicando restricciones sobre la base de datos. Si la muestra no conlleva capa gráfica explícita, en cuyo caso deben definirse necesariamente los campos con las coordenadas, las restricciones se aplicarán a partir de una sentencia SQL (Structured Query Language). Una vez seleccionado el total de la muestra a usar debe determinarse como se subdividirá en puntos de ajuste y de test.
La elección de qué puntos de la muestra serán puntos de ajuste y cuáles serán de test, puede dejarse como opción aleatoria indicando solo qué proporción (%) corresponderá a puntos de ajuste y cuál a puntos de test. Esta elección aleatoria puede originarse a partir de una semilla fija (generando submuestras reproducibles), o a partir de una semilla variable (obteniendo submuestras diferentes en cada nueva ejecución). También se ofrece la posibilidad de realizar esta elección gobernada por un campo de su base de datos: en este campo será necesario asignar un valor A para los puntos de ajuste y un valor T para los de test. También se ofrece la posibilidad de realizar una validación cruzada. En este caso el ráster resultado se obtiene usando todos los puntos como puntos de ajuste y, para hacer el test, se llevan a cabo una serie de iteraciones, en número igual al número total de puntos, donde en cada una de ellas se vuelve hacer el ajuste dejando fuera un punto para realizar el test. El RMS final se calcula como la raíz cuadrada de la mediana de los errores de cada iteración previamente elevados al cuadrado. Este tipo de validación es especialmente interesante cuando la variable dependiente tiene pocas muestras y no se puede prescindir de ninguna para usarlas como puntos de test. Utilizando la validación cruzada todas las muestras son a la vez de ajuste y de test.
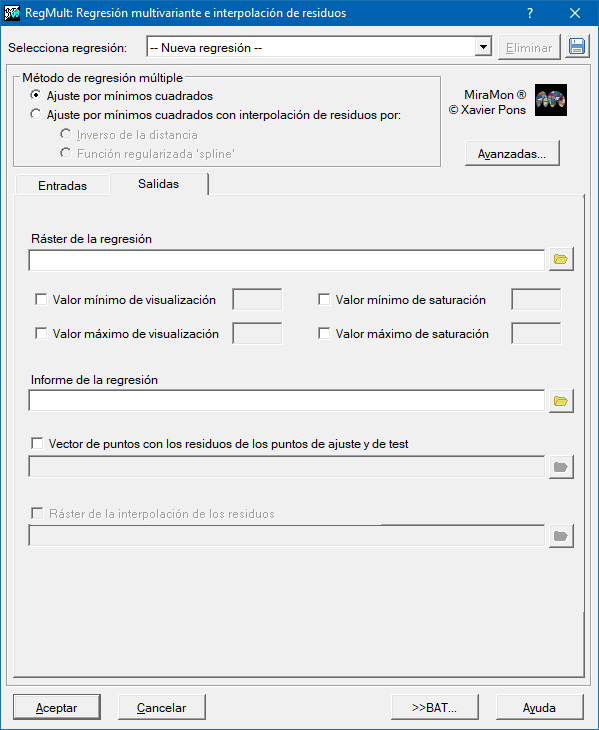
Los dos ficheros resultado obligatorios son un fichero de texto plano, que recoge información de cómo se ha realizado todo el proceso completo, y un ráster con el modelo predictivo.
El fichero de texto informa de qué opciones ha escogido el usuario, cuáles son los coeficientes ajustados de la regresión, tanto los que se usan para reproducir el modelo multivariante como los coeficientes normalizados (reducidos a rangos comparables de media 0 y desviación 1) para poder analizar la influencia de cada variable independiente en el modelo, qué variables independientes se han descartado y cuáles son los estadísticos principales de la regresión seleccionada y de la completa; finalmente se informa de la calidad del modelo mediante el RMS de los puntos de test, que también queda documentado en los metadatos de la capa resultado.
El ráster IMG resultado del modelo predictivo tendrá el mismo ámbito geográfico y tamaño de píxel que los rásters de las variables independientes; se puede delimitar, mediante una máscara de exclusión, las zonas donde no es necesario calcular el valor resultado (asignándose sindatos). El hecho de evitar calcular la solución del modelo en estas zonas puede acelerar considerablemente la velocidad de ejecución. También se pueden definir unos valores extremos de visualización (mínimo y máximo) que permitirán realizar mapas visualmente comparables al conseguir mantener constante la asignación entre el rango de valores y los colores de la paleta asignada.
Para más información se puede consultar la siguiente referencia:
Ninyerola M, Pons X, Roure JM (2000) A methodological approach of climatological modelling of air temperature and precipitation through GIS techniques. International Journal of Climatology 20: 1823-1841. DOI: 10.1002/1097-0088(20001130)20:14<1823::AID-JOC566>3.0.CO;2-B. https://rmets.onlinelibrary.wiley.com/doi/epdf/10.1002/1097-0088(20001130)20:14<1823::AID-JOC566>3.0.CO;2-B.

 |
| Caja de diálogo de RegMutlt |