-
 EstdGrup: Estadísticas de campos agrupando los registros en función de los valores presentes en otros campos
EstdGrup: Estadísticas de campos agrupando los registros en función de los valores presentes en otros campos
Acceso directo de la ayuda en Internet: EstdGrup
Acceso a la aplicación desde el menú: "Herramientas | Bases de datos alfanuméricas | Estadísticas de grupos de registros"
Presentación y opciones
Esta aplicació nrealiza cálculos estadísticos para uno o más campos de una base de datos (típicamente la relacionada con una capa vectorial estructurada), con la particularidad de que las variables estadísticas se calculan y clasifican según unas agrupaciones definidas por la persona usuaria.
Para definir la operación que realizará esta aplicación, los diferentes campos de la base de datos quedarán tipificados como campos agrupadores, campos calculados o simplemente campos no participantes.
Los campos agrupadores son aquellos que clasifican los resultados en función de los diferentes valores de cada uno de estos campos. Dado un campo agrupador, el programa determina cuántos y qué valores diferentes presenta la base de datos, organizada de forma relacional a partir de los identificadores de los objetos gráficos de la tabla principal; al conjunto de los diferentes valores de un campo encontrados se le llama proyección del campo. Para cada elemento de la proyección del campo agrupador, se calculan los valores estadísticos indicados para cada campo calculado.
Los campos calculados son aquellos campos de la base de datos de los que el usuario desea conocer determinados cálculos estadísticos. Sobre cada campo calculado el usuario puede escoger qué estadísticos desea calcular. En función del tratamiento que se de al campo (habitualmente cuantitativo para campos numéricos y categórico para el resto) el usuario podrá escoger entre los siguientes cálculos estadísticos:
-
Ambos tratamientos:
- Número de registros totales (incluye sindatos (1))
- Número de registros con datos (sin incluir sindatos
(1))
- Número de valores de un elemento de la proyección respecto el
número total, en porcentaje y sin considerar los sindatos
(1)
- Número de valores de un elemento de la proyección respecto el
número total, en porcentaje y considerando los sindatos
(1)
-
Tratamiento categórico:
- Moda; en el caso de moda no única, será el primer valor
(2)
- Porcentaje de ocurrencia de la moda excluyendo los valores
sindatos
- Índice de Shannon
- Primer valor (2)
- Último valor (2)
-
Tratamiento cuantitativo:
- Media
- Desviación estándar (dividiendo entre N)
- Variancia (dividiendo entre N)
- Sumatorio
- Rango (para enteros, 1+max-min)
- Mínimo
- Máximo
- Mediana
- Media de las desviaciones absolutas respecto de la mediana
(1) Sindatos para una base de datos incluye los valores sindatos explícitos, los registros vacíos y los registros en blanco.
(2) Para el tratamiento numérico la ordenación es la natural (1,2,3...), pero para el tratamiento categórico debe considerarse el tipo de ordenación utilizada; se usa una ordenación alfabética no estricta, basada en el orden de los códigos ASCII correspondientes a cada carácter. Esto implica que naturalmente A es anterior a B, pero en cambio a o á es posterior a B.
En los cálculos de cuantiles, como la mediana, puede indicarse, con el modificador /MEDIANA_EMPAT=, el tipo de desempate a usar para su cálculo cuando la posición del cuantil sea entre dos valores de la serie. Para más información se puede consultar sintaxis general.
El resultado del análisis estadístico puede presentarse en tres formatos:
- HTM: Se genera un único fichero en formato HTML que muestra para cada nivel de agrupación definido, los resultados estadísticos en forma de tablas.
- DBF: Para cada campo agrupador se genera una tabla DBF con tantos registros como valores tiene la proyección del campo agrupador y con la estadística de cada campo calculado como campos de esta tabla DBF.
- CSV: Se genera una hoja de cálculo en formato texto con separador de listas (típicamente el carácter ;), que tiene la misma estructura que el formato HTM.
En función de los formatos de salida, el programa presenta los siguientes modos de operación:
EstdGrup HTM:
Esta opción realiza cálculos estadísticos para uno o más campos de una base de datos (típicamente la relacionada con una capa vectorial estructurada), con la particularidad de que las variables estadísticas se calculan y clasifican según unas agrupaciones definidas por el usuario. Los resultados de los cálculos estadísticos se guardan en un fichero en formato HTML.
EstdGrup DBF:
Esta opción realiza cálculos estadísticos para uno o más campos de una base de datos (típicamente la relacionada con una capa vectorial estructurada), con la particularidad de que las variables estadísticas se calculan y clasifican según unas agrupaciones definidas por el usuario. Los resultados de los cálculos estadísticos se guardan en formato DBF en el directorio de destino.
EstdGrup CSV:
Esta opción realiza cálculos estadísticos para uno o más campos de una base de datos (típicamente la relacionada con una capa vectorial estructurada), con la particularidad de que las variables estadísticas se calculan y clasifican según unas agrupaciones definidas por el usuario. Los resultados de los cálculos estadísticos se guardan en un fichero en formato CSV.

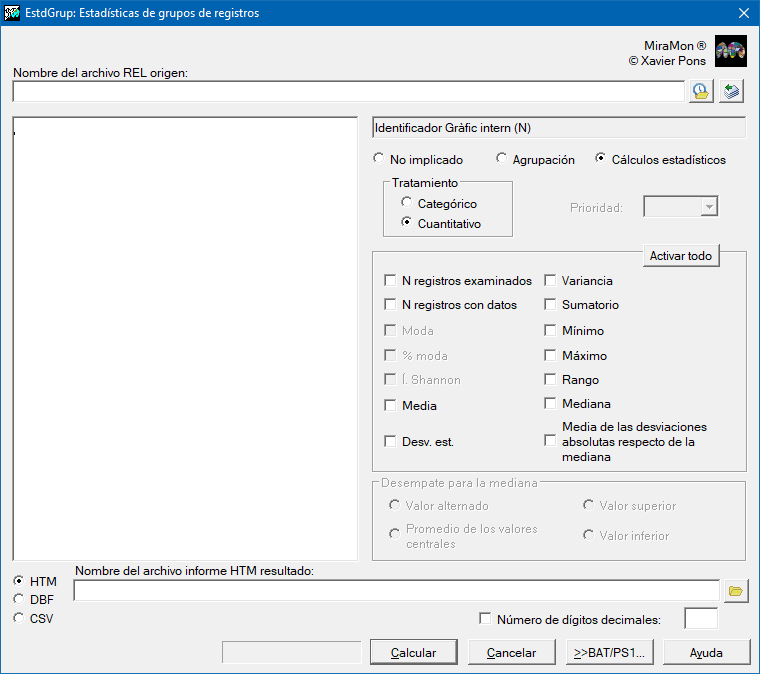
Caja de diálogo de la aplicación
|
| Caja de diálogo de EstdGrup |
Sintaxis
Sintaxis:
- EstdGrup Opción FicheroOrigen FicheroSalida [/GRP_#] [/ESTD_#] [/CAT_#] [/NUM_#] [/N_REG_TOTALS_#] [/N_REG_DADES_#] [/PRCNT_MODA_#] [/MODA_#] [/I_SHAN_#] [/MITJANA_#] [/DESV_STD_#] [/VAR_#] [/SUMA_#] [/MIN_#] [/MAX_#] [/PRCNT_GRUP_#] [/PRCNT_GRUP_NODATA_#] [/MEDIANA_#] [/DESV_MEDIANA_#] [/MEDIANA_EMPAT_#=] [/N_DECIMALS]
- EstdGrup Opción FicheroOrigen DirectorioDestino [/GRP_#] [/ESTD_#] [/CAT_#] [/NUM_#] [/N_REG_TOTALS_#] [/N_REG_DADES_#] [/PRCNT_MODA_#] [/MODA_#] [/I_SHAN_#] [/MITJANA_#] [/DESV_STD_#] [/VAR_#] [/SUMA_#] [/MIN_#] [/MAX_#] [/PRCNT_GRUP_#] [/PRCNT_GRUP_NODATA_#] [/MEDIANA_#] [/DESV_MEDIANA_#] [/MEDIANA_EMPAT_#=] [/N_DECIMALS]
- EstdGrup Opción FicheroOrigen FicheroSalida [/GRP_#] [/ESTD_#] [/CAT_#] [/NUM_#] [/N_REG_TOTALS_#] [/N_REG_DADES_#] [/PRCNT_MODA_#] [/MODA_#] [/I_SHAN_#] [/MITJANA_#] [/DESV_STD_#] [/VAR_#] [/SUMA_#] [/MIN_#] [/MAX_#] [/PRCNT_GRUP_#] [/PRCNT_GRUP_NODATA_#] [/MEDIANA_#] [/DESV_MEDIANA_#] [/MEDIANA_EMPAT_#=] [/N_DECIMALS]
Opciones:
- HTM (o 1): Se genera un informe del resultado de los cálculos estadísticos en formato HTML.
- DBF (o 2): Se generan tantas tablas en formato DBF como campos agrupadores en el directorio de destino. Cada tabla contiene los resultados estadísticos del correspondiente campo agrupador.
- CSV (o 3): Se genera una hoja de cálculo en formato CSV (que delimita los campos por un separador de listas) con el resultado de los cálculos estadísticos.
Parámetros:
- FicheroOrigen
(Fichero Origen -
Parámetro de entrada): Fichero REL correspondiente a la base de datos de una capa vectorial estructurada, o tabla DBF, a partir de la cual se realizarán los cálculos estadísticos seleccionados.
- FicheroSalida
(Fichero Salida -
Parámetro de salida): Para las opciones HTM (1) y CSV (3) es el fichero que contendrá los resultados de los cálculos estadísticos indicados.
- DirectorioDestino
(Directorio Destino -
Parámetro de salida): Es el directorio donde se escribirán los resultados en las correspondientes tablas DBF generadas para cada campo agrupador.
Modificadores:
/GRP_#= (Campo Agrupador #) Nombre del campo que actúa como agrupador con orden de prioridad #. El valor de esta variable contendrá un texto alfanumérico construido a partir del nombre del campo y sus relaciones desde la tabla principal. Se pueden usar N campos agrupadores (GRP_#), donde # es el número del campo agrupador (GRP_1, GRP_2,...). El orden de prioridad empieza por el valor 1, que indica el nivel de agrupación más general. Más consideraciones en sintaxis general. (Parámetro de entrada) /ESTD_#= (Campo estadísticas #) Nombre del campo sobre el que se realizan diferentes cálculos estadísticos identificados por el índice #, que solo tiene el significado de orden en que se muestran los diferentes campos calculados. Se pueden calcular estadísticos sobre N campos (ESTD_#). Su valor se constituye de la misma manera que /GRP_#. (Parámetro de entrada) /CAT_# (Tratamiento categórico) Indica tratamiento categórico del campo identificado por /ESTD_#. (Parámetro de entrada) /NUM_# (Tratamiento cuantitativo) Indica tratamiento cuantitativo del campo identificado por /ESTD_#. (Parámetro de entrada) /N_REG_TOTALS_# (Registros totales) Para el campo identificado por /ESTD_# se desea conocer cuál es el número de registros totales (incluye registros vacíos, blancos o sindatos). (Parámetro de entrada) /N_REG_DADES_# (Número de registros con datos) Para el campo identificado por /ESTD_# se desea conocer cuál es el número de registros con datos (sin incluir registros vacíos, blancos o sindatos). (Parámetro de entrada) /PRCNT_MODA_# (Porcentaje Moda) Indica que se desea conocer el porcentaje de ocurrencia del valor modal para el campo identificado por /ESTD_# en un tratamiento categórico. (Parámetro de entrada) /MODA_# (Cálculo Moda) Indica que se desea el cálculo de la moda para el campo identificado por /ESTD_# en un tratamiento categórico. (Parámetro de entrada) /I_SHAN_# (Índice de Shannon) Indica que se desea el cálculo del índice de Shannon para el campo identificado por /ESTD_# en un tratamiento categórico. (Parámetro de entrada) /MITJANA_# (Cálculo mediana) Indica que se desea el cálculo de la mediana para el campo identificado por /ESTD_# en un tratamiento cuantitativo. (Parámetro de entrada) /DESV_STD_# (Desviación estándar) Indica que se desea el cálculo de la desviación estándar para el campo identificado por /ESTD_# en un tratamiento cuantitativo. (Parámetro de entrada) /VAR_# (Varianza) Indica que se desea el cálculo de la varianza para el campo identificado por /ESTD_# en un tratamiento cuantitativo. (Parámetro de entrada) /SUMA_# (Sumatorio) Indica que se desea conocer el sumatorio de todos los valores para el campo identificado por /ESTD_# en un tratamiento cuantitativo. (Parámetro de entrada) /MIN_# (Mínimo) Indica que se desea conocer el valor mínimo para el campo identificado por /ESTD_# en un tratamiento cuantitativo, o el primer valor de una ordenación alfabética ascendente en un tratamiento categórico. (Parámetro de entrada) /MAX_# (Màximo) Indica que se desea conocer el valor máximo para el campo identificado por /ESTD_# en un tratamiento cuantitativo, o el último valor de una ordenación alfabética ascendente en un tratamiento categórico. (Parámetro de entrada) /PRCNT_GRUP_# (Número de valores válidos) Indica que se desea conocer el número de valores de un elemento de la proyección en relación al número total de valores para el campo identificado por /ESTD_#. En este cálculo no se consideran los valores sindatos. (Parámetro de entrada) /PRCNT_GRUP_NODATA_# (Número de valores considerando el sindatos) Indica que se desea conocer el porcentaje del valor respecto al número total de valores de la proyección para el campo identificado por /ESTD_#. En este cálculo sí se consideran los valores sindatos. (Parámetro de entrada) /MEDIANA_# (Mediana) Indica que se desea conocer la mediana de todos los valores para el campo identificado por /ESTD_# en un tratamiento cuantitativo. (Parámetro de entrada) /DESV_MEDIANA_# (Media de las desviaciones absolutas respecto de la mediana) Indica que se desea conocer la media de las desviaciones absolutas respecto de la mediana de todos los valores para el campo identificado por /ESTD_# en un tratamiento cuantitativo. (Parámetro de entrada) /MEDIANA_EMPAT_#= (Desempate de la mediana) Si se ha solicitado el cálculo de algún cuantil (como mediana, cuartil o percentil), indica el criterio de desempate a usar para su cálculo. Para saber más sobre los valores de este parámetro se pueden seguir las consideraciones del documento de sintaxis general. (Parámetro de entrada) /N_DECIMALS= (Número de dígitos decimales) Es el número de cifras decimales para los resultados de las estadísticas que corresponden a un valor numérico no-entero. Si no se especifica, se usa el valor definido en el fichero de configuración MiraMon.par. (Parámetro de entrada)