-
 ANSIOEM: Conversión o marcado del juego de caracteres en ficheros ANSI (Windows), OEM (DOS) o UTF-8
ANSIOEM: Conversión o marcado del juego de caracteres en ficheros ANSI (Windows), OEM (DOS) o UTF-8
ANSIOEM: Conversión o marcado del juego de caracteres en ficheros ANSI (Windows), OEM (DOS) o UTF-8| Presentación y opciones | Caja de diálogo de la aplicación |
| Ejemplos | Sintaxis |
Debido a la gran diversidad de caracteres que hay en los diferentes idiomas del mundo, a la necesidad de escribir símbolos especiales, y a la propia historia de la informática, se ha utilizado diferentes conjuntos de caracteres en diferentes países y bajo diferentes sistemas operativos. Como resultado de esto, es frecuente ver caracteres extraños, por ejemplo cuando leemos con un editor de texto plano, como el bloc de notas del Windows, un texto creado con un editor de texto plano de otro sistema operativo, como por ejemplo el EDIT del antiguo MS-DOS.
Este problema también podemos encontrarlo en las bases de datos, en las cuales hay campos de tipo texto en que los contenidos han sido escritos de acuerdo con alguno de los diversos conjuntos de caracteres existentes. En el caso concreto de las bases de datos en formato DBF hay una marca interna que, si está activada (valor mayor que cero), nos indica en qué conjunto de caracteres están escritos los textos, con lo cual es posible interpretarlos correctamente.
Este programa tiene varias opciones:
Muchos caracteres son transformables entre conjuntos de caracteres diferentes; por ejemplo tanto el conjunto de caracteres OEM-850 del MS-DOS, el ANSI 1252 de Windows como el UTF-8 contienen todas las letras mayúsculas y minúsculas acentuadas. Asimismo, algunos caracteres sólo existen en algunos conjuntos de caracteres; por ejemplo, el símbolo de marca registrada (TM), que en la tabla ANSI 1252 se puede representar con un solo carácter volado, no tiene representación en la tabla OEM-850. En estos últimos casos la conversión no es posible y hay que poner un carácter substituto arbitrario que nos indicará que en la traducción el conjunto de caracteres de destino no tiene ningún carácter suficientemente parecido al carácter en el conjunto de caracteres original.
Atención: Nunca se debe convertir un fichero que no sea de texto plano o DBF o se corromperá su contenido. Ejemplos de ficheros de texto plano son los REL y MMM de MiraMon, los ficheros TXT, BAT, etc.
Notas:
Algunas marcas posibles para ANSI en tablas DBF son:
'ascii ANSI' 87 (0x57) (dBASE)
'WEurope ANSI' 88 (0x58) (dBASE) [defecto del programa]
'Spanish ANSI' 89 (0x59) (dBASE)
'FoxPro ANSI' 3 (0x03) (FoxPro)
Para marcar una tabla de acuerdo con uno de estos conjuntos de caracteres se debe indicar el valor numérico decimal (por ejemplo 3 para FoxPro ANSI). MiraMon y MiraDades reconocen todas estas marcas.
Algunas marcas posibles para OEM-850 en tablas DBF son:
'dbDUTCH2 dBASENLDcp850' 10 (0x0A) (dBASE)
'dbFRENCH2 dBASEFRAcp850' 14 (0x0E) (dBASE)
'dbFRENCHCAN2 dBASEFRCcp850' 29 (0x1D) (dBASE)
'dbGERMAN2 dBASEDEUcp850' 16 (0x10) (dBASE)
'dbITALIAN2 dBASEITAcp850' 18 (0x12) (dBASE)
'dbPORTUGUESE2 dBASEPTBcp850' 37 (0x25) (dBASE)
'dbSPANISH2 dBASEESPcp850' 20 (0x14) (dBASE) [defecto]
'dbSWEDISH2 dBASESVEcp850' 22 (0x16) (dBASE)
'dbUK2 dBASEENGcp850' 26 (0x1A) (dBASE)
'dbUS2 dBASEENUcp850' 55 (0x37) (dBASE)
'FoxPro OEM-850' 2 (0x02) (FoxPro)
Para marcar una tabla de acuerdo con uno de estos conjuntos de caracteres se debe indicar el valor numérico decimal (por ejemplo 14 para FRENCH2). MiraMon y MiraDades reconocen todas estas marcas.

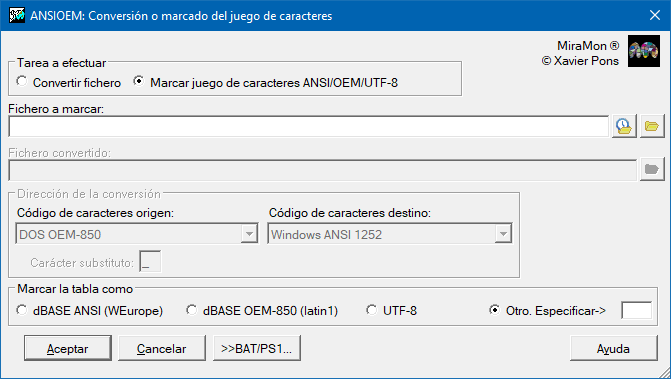 |
| Caja de diálogo de ANSIOEM. |
ANSIOEM C:\COPIA\LEE.TXT D:\LEE.TXT 1 ANSIOEM C:\COPIA\LEE.TXT D:\LEE.TXT 1 ANSIOEM C:\BASES\COMAR.DBF A:\COMAR 3 ANSIOEM C:\BASES\MUNICIP ANSI ANSIOEM C:\BASES\MUNICIP 5 ANSIOEM C:\BASES\COMAR.DBF A:\COMAR_EN_UTF8.DBF 5 |
| Ejemplos de la aplicación de ANSIOEM. |